Management Server – Firebox synchronisiert nicht
Bei der Nutzung des Management Servers kann es im fully managed mode dazu kommen, dass die Firebox nicht synchronisiert.
Folgende Symptome deuten auf dieses Problem hin:
Bei der Nutzung des Management Servers kann es im fully managed mode dazu kommen, dass die Firebox nicht synchronisiert.
Folgende Symptome deuten auf dieses Problem hin:
 Das Debug Log Level für die Konsole (System Manager => Traffic Monitor)
Das Debug Log Level für die Konsole (System Manager => Traffic Monitor)
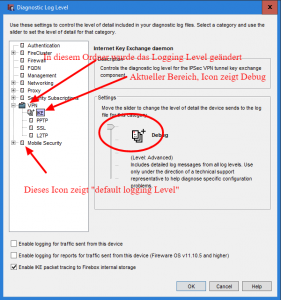
kann im Policy Manager unter
Setup => Logging => Klick auf [Diagnostic Log Level]
eingestellt werden. Hier stellt man den Bereich VPN > IKE auf „Debug“
und speichert die Konfiguration auf die WatchGuard.
Nicht vergessen: nach Gebrauch das Log Level wieder zurückstellen 🙂
Das Debugging einer problembehafteten HA Umgebung aus zwei X750e mit Fireware XTM 11.3.2 (ich betrachte diese Version derzeit für Cluster aus X Core / Peak e-series am stabilsten) hat heute einen netten Sonderfall aufgezeigt, der für die Störungen sicher mitverantwortlich war:
Der Kunde betreibt schon seit vielen Jahren ein WatchGuard VPN mit ca. 40 Außenstellen. Wie so oft hat in der Vergangenheit dafür eine einzelne Company Connect Anbindung der Telekom mit 2 Mbit/s gereicht. Diese Leitung war mit redundanten Cisco-Routern und zudem einer Zweiwegeführung ausgestattet. Der Kunde hatte nun bei der Telekom eine weitere Company Connect Anbindung beauftragt, mit 34 Mbit/s und ebenfalls redundanten Cisco-Routern und Zweiwegeführung. Auf der WatchGuard waren diese beiden Anbindungen als Multi-WAN konfiguriert – im Failover-Modus.
Bei einem Routine-Check des „Status Report“ im Firebox System Manager ist mir in der ARP Table der WatchGuard aufgefallen, dass dort beide vorgelagerten Router-Paare (2 Mbit an eth0 und 34 Mbit an eth1) mit der gleichen Hardware MAC Adresse 00:00:0C:07:AC:01 aufgeführt waren.

Recherche hat ergeben, dass dies eine virtuelle MAC-Adresse ist, die von redundanten Cisco-Routern im HSRP Modus verwendet wird – und zwar dann, wenn auf den Routern die HSRP Group ID = 1 eingestellt ist. Offenbar hat der ISP also beide Router-Paare (da verschiedene Einzelaufträge) per Default mit der gleichen HSRP Group versehen… Das wird auch erst dann zum Problem, wenn beide Leitungen wie im vorliegenden Fall an das gleiche System angeschlossen werden. Die Auswirkungen kann man sich ausmalen.
Ein Support Call bei der Telekom hat dazu geführt, dass ein Router-Paar auf die HSRP Group ID = 2 eingestellt wurde, wodurch sich die virtuelle MAC-Adresse auf 00:00:0C:07:AC:02 geändert hat und nunmehr aus Sicht der WatchGuard die Interfaces sauber konfiguriert sind:

Ich habe aktuell einige offene Support-Fälle, die folgende Gemeinsamkeiten aufweisen: Active/Passive Cluster unter Fireware XTM v11.3.x, Branch Office IPSec VPN Tunnel zu festen Außenstellen, Kommunikationsprobleme innerhalb des/der BOVPN Tunnel.
In allen Fällen scheinen die Probleme mit fehlerhafter Fragmentierung von IPSec-Paketen zu tun zu haben. Ich konnte etwas ausführlicher debuggen und feststellen, dass bisweilen (also nur zeitweise!) IP-Pakete größer als 1394 Bytes im VPN-Tunnel nicht korrekt fragmentiert, sondern komplett verworfen werden. WatchGuard hat das Szenario im TestLab nachgestellt, konnte jedoch die Fehlerursache bis jetzt noch nicht weiter eingrenzen.
Zur schnellen Dokumentation des Problems verwende ich von einem PC in einer Außenstelle eine MSDOS-Eingabeaufforderung mit dem Befehl
ping [IP] -l 2000 -t
wobei [IP] eine IP-Adresse am anderen Ende eines BOVPN-Tunnels (in der Zentrale) ist. Der Befehl erzeugt Ping-Pakete mit einer Größe von 2000 Byte, die also beim Transport über das Internet zwingend fragmentiert werden müssen, da die maximale MTU Size auf Internet-Routern in der Regel 1500 Bytes beträgt. Erhalte ich korrekte ICMP-Antworten, weiss ich, dass die Fragmentierung korrekt funktioniert. Wenn nicht, liegt ein Problem vor. Durch Verkleinern der Paketlänge kann man sich iterativ an den kritischen Wert herantasten. Im vorliegenden Problemfall werden Pings mit 1394 Bytes korrekt übertragen, Pings mit 1395 Bytes und mehr jedoch NICHT:

Das Problem scheint zudem nur auf dem Rückweg von dem angepingten Host aufzutreten. Offenbar erreichen im Problemfall auch größere Datenpakete den Zielhost, der auch korrekt antwortet – jedoch scheint die WatchGuard Firebox ein Problem mit dem „Rücktransport“ der Antwortpakete zu haben, wie sich am Vergleich der folgenden, im Abstand von ein paar Minuten aufgenommenen Screenshots erkennen lässt. Die mit grünen Streifen markierten Werte zählen im Laufe der Zeit korrekt hoch, während der eine rot markierte Wert (RCVD zurück auf dem ursprünglich sendenden System) sich nicht ändert…:

In allen meinen Support-Fällen konnte ich das Problem zunächst durch einen Workaround umgehen: auf dem Cluster Reduktion der MTU Size auf den Interfaces, die an BOVPN-Tunneln beteiligt sind, von 1500 auf 1380 Bytes:

WatchGuard muss jedoch das eigentliche Problem finden und beheben, denn durch den Workaround wird die Gesamtleistung der WatchGuard Firebox etwas ausgebremst.
WatchGuard Firebox e-series und XTM Systeme mit Software 10.x oder 11.x bieten auch die Möglichkeit der Administration und Programmierung im Kommandozeilenmodus (CLI). Ausnahme: X Edge e-series mit v10.x. Hierzu läuft auf der WatchGuard ein SSH-Daemon, der auf Port 4118 tcp hört. Dieser Port ist Bestandteil der standardmäßig im Regelwerk enthaltenen Firewall-Regel „WatchGuard“, die ebenfalls standardmäßig den Zugriff auf die „Firebox“ von „Any-Trusted“ und „Any-Optional“ ermöglicht. Das From-Feld dieser Regel kann natürlich auch so erweitert werden, dass der Zugriff über das Internet oder für mobile User möglich wird (Sicherheitsüberlegungen berücksichtigen!).
Das CLI kennt wie das WebUI zwei User: status und admin. Zu status gehört immer das lesende Kennwort der Firebox (status passphrase). Zu admin gehört immer das schreibende Kennwort der Firebox (configuration passphrase).
Wenn Sie nun über einen SSH-Client (z.B. PuTTY) eine SSH-Verbindung zu Port 4118 öffnen und sich als admin an der Firebox anmelden, können Sie dort zunächst durch die Eingabe eines Fragezeichens (?) eine Übersicht der verfügbaren Befehle anzeigen lassen:

Hier findet sich unter anderem auch der Befehl „reboot“, über den die Firebox durchgebootet werden kann. Gerade bei Fireboxen mit v10.x ist dieser Einstieg manchmal „der letzte Rettungsanker“, wenn durch Memory Leak Effekte der Hauptspeicher auf der Firebox zugelaufen ist und die Firebox in Folge den Daemon abgeschaltet hat, über den sich der WSM mit der Firebox verbindet…
Ebenfalls sehr hilfreich ist der CLI-Befehl „ping“, der es ermöglicht, pings direkt von der Firebox aus zu verschicken.
Theoretisch kann über das CLI auch eine weitgehende Administration des Gesamtsystems erfolgen, also auch Konfigurationsänderungen etc., jedoch kommt dies in der Praxis eher selten vor. WatchGuard bietet hierfür unter http://www.watchguard.com/help/documentation/xtm.asp eine umfangreiche PDF: die Command Line Interface Reference.
Die WatchGuard Firewall prüft jede neu anstehende Verbindung von einem Host auf der einen Seite der Firewall zu einem Host auf der anderen Seite der Firewall. Dabei werden zunächst die Header der IP-Pakete untersucht: Quell-IP-Adresse, Ziel-IP-Adresse, Quell-Port, Ziel-Port, verwendetes Protokoll (TCP, UDP, ICMP etc.). Die Firewall durchforstet nun das Regelwerk sequentiell „von oben nach unten“ (wenn man sich in der Standard-Listenansicht des Policy Managers befindet).
Nacheinander wird jede einzelne Regel geprüft, ob sie die o.g. Kriterien erfüllt – so lange bis der erste „Treffer“ gefunden wird. Nur diese Regel wird auch ausgeführt. Gibt es „weiter hinten“ im Regelwerk eine andere Regel, auf die ebenfalls die o.g. Kriterien zutreffen, wird diese niemals erreicht/ausgeführt. Wird eine passende Regel gefunden, wird die Verbindung authentisiert und (bei TCP) in die TCP Session Table der Firewall eingetragen. Nachfolgende Pakete in der gleichen TCP-Verbindung werden dann automatisch von der Firewall durchgelassen und nicht noch einmal aufs Neue authentisiert (anders bei Application Proxy Regeln, die eine zusätzliche Kontrolle des Inhalts vornehmen).
Ganz am Ende des Regelwerks steht eine unsichtbare Deny Regel. Jeder Datenverkehr, der nicht ausdrücklich durch eine Firewall-Regel zugelassen wird, wird von dieser Default Deny-Regel ABGELEHNT. Je nachdem, ob der Verbindungsaufbau von innen oder von außen erfolgen sollte, erscheint im Traffic Monitor und im Logfile ein Unhandled Internal Packet oder ein Unhandled External Packet.
Warum werden die Unhandled Packets angezeigt?
Weil im Policy Manager bei Setup > Default Threat Protection > Deafult Packet Handling > Logging das Häkchen „Send Log message“ bei den Kategorien „Unhandled Internal Packet“ und „Unhandled External Packet“ gesetzt ist. Das Logging könnte zwar durch Entfernen des Häkchens ausgeschaltet werden – das ist aber keine gute Idee (bessere Idee weiter unten :-). Der Traffic Monitor und die Unhandled Packets sind ein extrem wichtiges und hochinteressantes Tool, um Fehlverhalten von Maschinen bzw. Fehlkonfigurationen im lokalen Netzwerk aufzudecken und abzustellen! Die Anzeige der Denied Packets kann der Administrator auch sehr gut nutzen, um den Bedarf für neue Regeln zu erkennen und wie diese auszusehen haben.
Das Default Regelwerk und die globale Outgoing-Regel
Der Quick Setup Wizard erzeugt bei der Ersteinrichtung der WatchGuard Firebox ein kleines Default Regelwerk, das im Prinzip sämtlichen TCP- und UDP-Verkehr sowie Ping in ausgehende Richtung (outgoing) zulässt – und sämtlichen eingehenden Verkehr (incoming) verbietet.
Gewissenhafte Administratoren wollen jedoch genau definieren, welcher ausgehende Datenverkehr zulässig ist und diesen auf Maschinen- und/oder User-Ebene auf das absolute Minimum beschränken. Neue Firewall-Regeln werden ins Regelwerk aufgenommen und so weit wie möglich einschränkt. Ein gutes Firewall-Regelwerk wächst dadurch auf 20-30 Regeln, teilweise aber auch auf 80-100 Regeln an. Das schöne feingliedrige Regelwerk wird aber nur dann wie beabsichtigt funktionieren, wenn die defaultmäßig vorhandene Outgoing-Regel auf disabled gesetzt oder ganz gelöscht wird. Denn: das Regelwerk wird „von oben nach unten“ abgearbeitet, der erste Treffer zählt. Solange „unten“ die globale Outgoing-Regel steht, nützen die Einschränkungen weiter „oben“ nichts. Der Verkehr würde trotzdem über die Outgoing-Regel rausgehen, also weg damit!
Anzeige von bestimmten Unhandled Packets unterdrücken
Bisweilen ärgert man sich doch über die Anzeige von Unhandled Packets. Eventuell kann man die Ursache dafür einfach nicht abstellen usw. Bei der Lösung hilft nun das bisher Gesagte: das unzulässige Paket erzeugt eben ein Unhandled Packet, weil es eben keine explizite Regel für diesen Verkehr gibt. Das Paket bleibt an der unsichtbaren Deny Regel ganz am Ende des Regelwerks hängen.
Der Trick besteht nun einfach darin, eine explizite Firewall-Regel zu bauen, die den Verkehr genau beschreibt (siehe oben: Quell-IP, Ziel-IP, Quell-Port, Ziel-Port, Protokoll), aber verbietet („Denied“) – und das Logging ausschaltet. Der lästige Verkehr taucht künftig nicht mehr im Traffic Monitor und im Logfile auf. Im Regelwerk werden Deny-Regeln mit einem roten X angezeigt:

Konfigurationsbeispiel: HostWatch Namensauflösung (Port 137/udp) unterdrücken

Properties > Logging

Eine Denied-Regel verankert sich im Regelwerk automatisch OBERHALB einer Allow-Regel für den gleichen Port bzw. das gleiche Protokoll, wird also zeitlich gesehen früher geprüft. Das kennen wir: ein explizites Verbot ist mächtiger als eine nicht erfolgte Erlaubnis. Ich nutze die Kombinationsmöglichkeit aus Denied- und Allow-Regeln auch ganz gerne so: Ping.Allow von Any nach Any -und- Ping.Denied von Any-External nach Firebox. Damit kann innerhalb des lokalen Netzwerks/VPN fröhlich hin- und hergepingt werden – auf Pings aus dem Internet reagiert unsere Firebox jedoch nicht. Wenn’s stört, kann für die Denied-Regel natürlich auch das Logging ausgeschaltet werden…
Im Zusammenhang mit meinem Posting „Upper Port Problem bald gelöst“ vom 08.01.09 kam folgende Frage auf: „Wie kann man feststellen, ob/wann überhaupt ein Kernel Crash aufgetreten ist?“ Hier die Antwort: Starten Sie den WatchGuard System Manager (WSM), verbinden Sie sich mit Ihrer Firebox und rufen Sie über Rechtsklick den Firebox System Manager auf. Gehen Sie dort auf die Registerkarte „Status Report“ und scrollen Sie bis ganz unten. Endet die Anzeige mit
** Routing Protocol (BGP)
**
bgp is not enabled
liegt kein unmittelbarer Kernel Crash vor. Gibt es darunter jedoch noch ein paar Zeilen zum Thema VM Dump, dann sind ein oder mehrere Kernel Crashes aufgetreten:
**
** VM Dump
**
Found kernel crash, time of crash was Sun Jan 11 21:14:26 2009
Crash dump data recovered on Sun Jan 11 21:15:08 CET 2009
Crash dump data saved in /var/log/vmdump/vmdump.3.

In diesem Beispiel bedeutet die Ziffer 3 ganz zum Schluss, dass aktuell sogar vier Kernel Crashes in den internen Support Logfiles der WatchGuard Firebox protokolliert sind. Ein Kernel Crash löst anschließend einen Reboot der Firebox aus.
„Wie kann ich die internen Support Logfiles auslesen?“
Antwort: Ganz rechts unten in der Ecke des Status Reports (vgl. auch den o.g. Screenshot) findet sich ein Button „Support…“:

Mit Klick auf „Retrieve“ kann man alle internen Logfiles in einer gemeinsamen Datei namens support.tgz auf die Windows Management-Station herunterladen. Dort kann sie z.B. mit Hilfe von WinZip oder WinRAR ausgepackt werden. Im Unterverzeichnis varlogvmdump finden sich im aktuellen Beispiel die Dateien vmdump.0, vmdump.1, vmdump.2 und vmdump.3 – jeweils mit Datum und Uhrzeit des tatsächlichen Kernel Crashes:

Da alle Uhrzeiten recht ähnlich sind, liegt ein Vergleich mit den Uhrzeiten der 24-stündigen T-DSL Zwangstrennung durch die Telekom nahe (adsl.log). Und siehe da: ja, passt. Im vorliegenden Beispiel steht die T-DSL-Zwangstrennung im direkten Zusammenhang mit den Kernel Crashes… 🙁
Die Firebox X Edge hat eine nicht dokumentierte Seite, die zum Testen und für Debug-Zwecke sehr hilfreich ist:
https://IP-DER-FIREBOX/shakne.htm.
Im Abschnitt Property Management können mit den Funktionen „Get Property“, „Put Property“ und „Delete Property“ einzelne Parameter in der Konfigurationsdatei hinzugefügt, verändert und gelöscht werden, die über die GUI sonst nicht erreichbar wären. Ähnlich wie beim manuellen Eingriff in die Registry eines Windows-Rechners ist hier natürlich ein konkreter Anlass und äußerste Sorgfalt angesagt!
Die Funktion Ping setzt einen Ping direkt von der Firebox an die eingegebene Zieladresse ab. Das ist äußerst hilfreich, z.B. wenn man sich gerade einmal nicht auf anderes Testsystem an dem Standort aufschalten kann…

Weiter unten finden sich noch verschiedene Debug-Hilfen – unter anderem kann hier auch das Logging Level für die Application Proxies hochgesetzt werden (wirklich nur für Debug-Zwecke, denn natürlich erzeugt das erweiterte Logging Last auf der Firewall…)

